

The choice of Apache Pulsar
Building a distributed event-driven "workflow as code" orchestration engine

Hello,
In my last email, I’ve told you I’d decided to develop an open-source alternative to Zenaton after its closing.
Why not open-sourcing Zenaton’s code?
Zenaton was built with Elixir, a superset of Erlang. At Zenaton beginnings, it appeared a good idea - it was even our secret sauce as we were super quick to prototype our first engine. Unfortunately, it became later a liability when we realized that we vastly underestimated the strategic importance for Zenaton of reliable and scalable storage. Elixir has super-powers to build always alive, massively parallel systems, such as messaging or real-time multi-player games - but if you need to assemble it with long-term scalable storage, you are basically on your own. And we've learned the hard way that building a reliable distributed system is tough.
As the whole idea of open-sourcing Zenaton was to target large companies' technical teams, we needed to propose a scalable technology.
It appeared daunting, and let’s say it irrealistic for only Pierre-Yves and me to fix this existing complex system by ourselves. And frankly, I would not have even dared to try that if I'd not stumbled upon Apache Pulsar (thanks to Quentin).
Using Apache Pulsar
Apache Pulsar is sometimes described as the next Kafka. It has an impressive set of useful features (unified messaging system, horizontal scaling, stateful computations, delayed messages, natively multi-tenant, native Geo-replication). They made Pulsar an ideal choice for being our technical foundation. I’ve written a comprehensive article to describe why. That’s how Pulsar gave us the confidence we needed to rebuild everything on top of a modern stack. By handling the difficulties of building stateful distributed systems, we could focus on what we were the best at - coding a “workflow as code” engine. (That’s also the reason why we started Zenaton in Kotlin, a modern JVM-compatible language).
But there are no such things as a silver bullet. And soon, we realized that some of Pulsar’s newest features were in developer preview and were actually buggy - especially the handy functions state storage. It means that we will have to wait until early 2021 and the 2.8 version to reach the initial vision of Infinitic being deployed on top of a Pulsar cluster without additional infrastructure.
This setback also has had a positive impact: as we did not want to wait until then to test Infinitic - it pushed us to refactor Infinitic with clear interfaces to run Infinitic with different infrastructures than Pulsar.
Infinitic architecture
Infinitic event-based 's architecture is now organized around:
a transport layer, moving messages between engines and workers
a first storage layer, transiently storing states of running tasks and workflows
a second storage layer - only used by dashboards - permanently storing all events
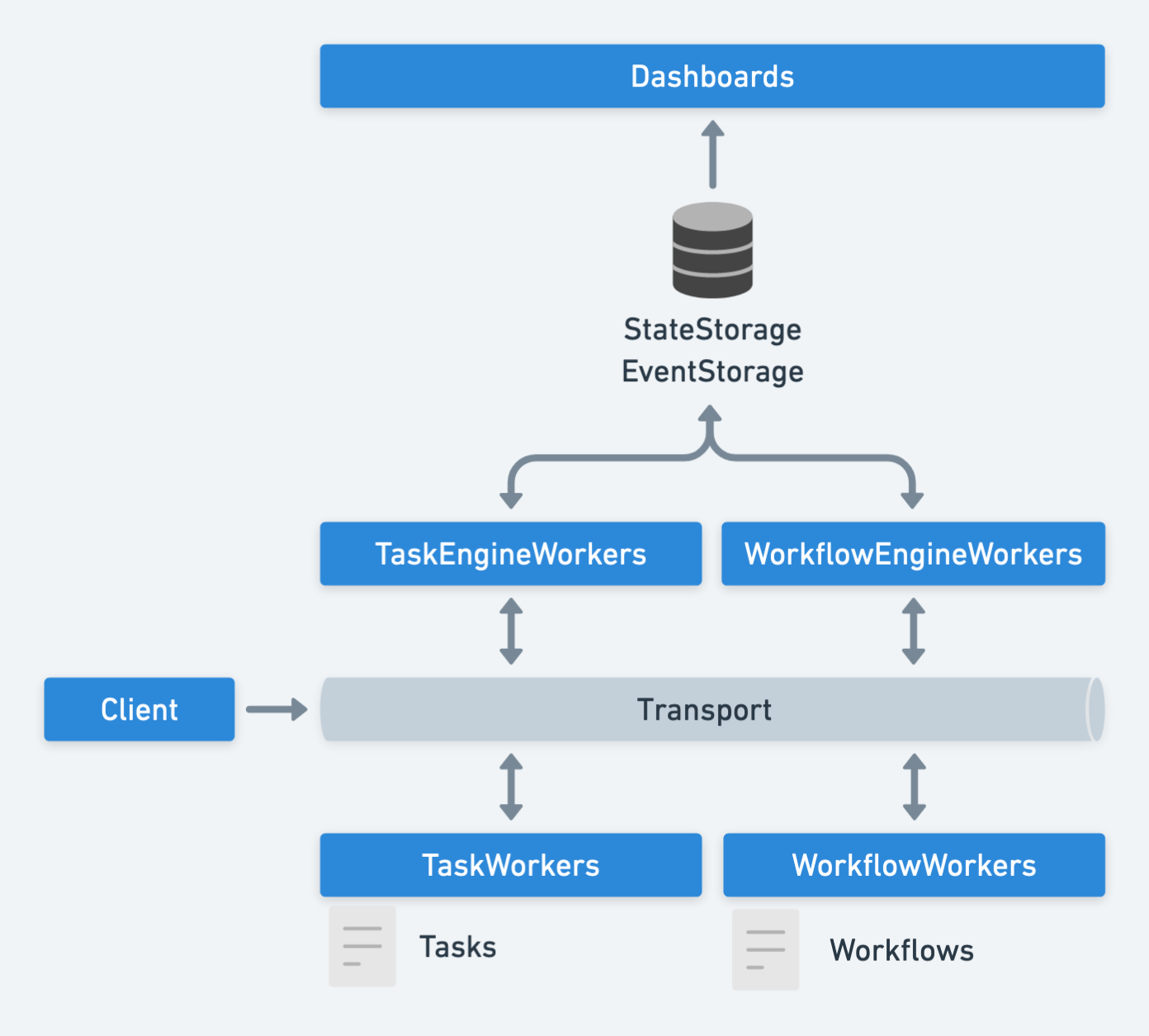
Today, the existing implementations are :
transport: Pulsar
state storage: Pulsar (2.8), Redis, In-Memory (useful for tests)
event storage: Pulsar
We performed some very promising load/reliability tests using Pulsar and Redis for state storage.
Conclusions
I believe that our bet on Pulsar was a good one for Infinitic. The Pulsar community is growing fast, and the tech itself is quickly maturing. We keep Pulsar as our primary target for Infinitic implementation as it’s the best bet for reaching “infinite” scalability. Nevertheless, we've taken some time to build the Infinitic core around clearly defined interfaces that will allow us to use different technologies for transport (RabbitMQ…) or storage (Redis…).
That’s all for today. If you have questions, do not hesitate to reply to those emails, I’d happily discuss them.
Best,
Gilles